




Merhabalar :)
Kendime ve size not:
Burada local win10 üzerinde yolov5 kullanarak kendi nesne algılama modelimizi nasıl eğiteceğimiz ile ilgili bilgiler bulacaksınız.
YOLOv5 ortamımızı hazırlamak için birden çok yöntemimiz mevcut tabi ki en kolayı fcakyon hocamın geliştirdiği pip paketi hemen aşağıda bir satırlık kod ile yolov5 ortamını hazırlamak mümkün kendisine alana olan katkılarından dolayı teşekkür ediyoruz. Literatüre özellikle geniş alan gözetleme konusunda öne çıkan sahi kütüphanesi ile katkıları azımsanmayacak kadar büyük 👏 Bu yönde çalışmalar yapıyorsanız takip etmeniz önerilir @fcakyon linkedin
pip install yolov5
Diğer bir yöntem olan yolov5'in kendi git reposundan kurulum için de şuradan eski bir blog yazıma bakabilirsiniz.
Ortamı hazırladığımıza göre ilerlemek için bir problem yaratalım ;)
Trafikte her gün karşılaştığımız trafik işaretlerini tanıyan bir model geliştirmek istediğimizi varsayalım.
Nesne algılama modelleri için en önemli kısım aslında veri toplama kısmıdır. Tanıtacağınız nesneler ile ilgili ne kadar çok ve çeşitli görsel bulursanız o kadar iyi olacaktır.
Burada karşımıza çıkan soru şu. Kaç sınıfımız var ve her bir sınıf için ne kadar örnek toplamamız gerekir.
Kimse bu noktada size net bir sayı veremeyecektir. Bu konuda literatürde farklı varsayımlar olsa da veri toplama probleme özgü olacağından net bir şey söylemek mümkün değildir.
Fakat yapılan başarılı çalışmalar üzerinden yada çalıştığınız problemle benzer çalışmaları dikkate alarak bir tahmin yürütmek tabi ki mümkün ama sonuç olarak modelinizi denediğinizde verilerinizin yeterli olup olmadığını görmüş olursunuz.
Ayrıca burada öne çıkan bir diğer önemli durum ise yapacağınız öğrenme türü, örnek vermek gerekirse transfer öğrenme yapacaksanız bulacağınız örnek sayısı ile sıfırdan öğrenme yapacaksanız örnek sayınız arasında bir hayli fark olacaktır. Transfer öğrenme ile çok az örnekle öğrenmeyi gerçekleştirmeniz mümkün olacaktır. Tabi transfer öğrenmeyi seçmeniz durumunda daha önce iyi yapılandırılmış bir modelin konforundan da yararlanmış olacaksınız. Aksi durumda sıfırdan bir model tasarımında sizleri veri toplamak dışında model yapılandırma gibi güzide bir sorun beklemekte :) Bu konuda ne diyor bu diyorsanız ufak bir araştırma yapmanızı öneririm.
Bir diğer handikap anchor box destekli bir model kullanacaksanız modeldeki sınıfların tanınması için hayati öneme sahip anchor box'ın önceki nesne ve yeni nesnelerle uyumlu olması gerektiğidir. Bu handikap anchor box destekli modellerin başka bir probleme uyarlanmasındaki en büyük sorundur. Bu durumla ilgili ufak bir araştırma yapmanızı öneririm.
Bu noktada bahsetmemiz gereken bir diğer durum ise veri toplama aşamasında araştırmacıların yeterli veriye ulaşamaması durumunda veri büyütme (augmentation) işlemine başvurmalarıdır. Aşağıda buna yönelik bir örnekte görebilirsiniz. Veri büyütme yeterli veriniz olmadığında başvurmanızı önereceğim bir yöntem ki yolov5 de dahil yapay sinir ağları çerçeveleri bunu destekler.

Bahsedilen her bir handikap makalelere ve araştırmalara konu olan tartışmalar ve bu yazının konusu değiller, belki başka bir yazıda bu konularda konuşabiliriz.
Yukarıda sayılanları özetleyecek olursak;
Toplayacağınız verilerin boyutunu sınıf sayınız ve probleminiz belirleyecektir.
Modelinizi eğitirken kayıp, doğruluk ve keskinlik değerlerini doğru değerlendirmeli ve buna göre müdahale edip etmemeyi seçmelisiniz.
Model eğitiminde önceki bir modelin ağırlıklarından yararlanıp yararlanmamanız çok önemlidir. Bu çalışmada bizim yapacağımız gibi önceki bir modelin ağırlıklarından yararlanacaksanız nispeten küçük bir veri boyutu işe yarayabilir. Bu noktada kaçırmamanız gereken nokta eğer anchor box tabanlı bir modelse anchor ayarlarının nesneleriniz için uygun olup olmadığına dikkat etmelisiniz.
Model eğitiminde omurga dahil başka hiçbir modelden yararlanmadan tamamen kendinize özgü bir model geliştiriyorsanız, bu noktada sizi uzun deneme yanılma ve literatür araştırmasının beklediğini unutmayın.
Veri boyutunun çok fazla değişkenden etkilendiğini bu noktada gri bir alan olduğunu kabul etmek gerekir. Kesin olarak konuşacağınız bir istatistiki bilgi maalesef en azından bende yok.
Yukarıda ki bahsedilen problemin çözülmesi için bu noktada ben yaklaşık 4 tane sınıf belirliyor ve bu sınıflara ait verileri toplamak için kolları sıvıyorum.
Sınıflar:
Dur Tabelası
Durak Tabelası
Trafik Işığı
Park Tabelası
Bu sınıflar için toplamda 1300 adet görüntü ile verileri etiketleme işlemlerine geçebiliriz. Bu görüntüleri öncelikle google street view ve github'ta oluşturulan ituracingdriverless/TTVS görüntü deposundan yararlanarak oluşturdum.
Verileri etiketleme ( sınırlayıcı kutu ile çerçeveleme) işlemleri için [labelImg]github.com/tzutalin/labelImg) kullanacağız, bu işlem maalesef manuel olarak yapılıyor ve nesne algılama problemleri için hem hayati hem de en çok efor sarf ettiğimiz kısım oluyor. Fakat yukarıda bahsettiğim TTVS gibi bir çok takım veya kişinin bir araya gelerek oluşturduğu depolar bu noktada sizlere hazır etiketlenmiş görüntüler sağlayabilir sizlerde katkıda bulunarak bu tür datasetlerin büyümesini sağlayabilirsiniz". Bu noktada ilgilendiğimiz probleme özgü tür bir girişimi başlatan ituracingdriverless takımına canı gönülden teşekkür etmek isterim.
LabelImg bu noktada tek çözüm değildir. Etiketleme işlemleri için localde veya online olarak çözüm getiren pek çok çözüm mevcut, aramaya inanın :)
Etiketleme işlemleri için teknik ayrıntıları Sayın Ömer Şenol'un Şu blog yazısından alabilirsiniz.
Etiketleme bilgilerinin tutulduğu dosya türünü Pascal/VOC, YOLO veya CreateML seçebildiğinizi görmüşsünüzdür. Açıkçası YOLO üzerinde çalıştığımız için etiketleme yapımızı YOLO (.txt) olarak seçmek ilk seçenek gibi dursa da benim bu noktada sizlere tavsiyem içerdiği fazlaca bilgi ve dönüştürmek kolay olduğundan PascalVOC (.xml) yapısını seçmeniz yararınıza olacaktır. Çünkü bu problemle ilgilenirken sadece YOLO ile sınırlı olmayacak şekilde farklı modelleri denemek isteyeceksiniz bu noktada .xml dosyaları size çok daha yardımcı olacaktır.
Buraya etiketleme yapısını PascalVOC'tan YOLO yapısına çeviren ufak bir scriptin adresini de bırakalım. Bu çevirme işlemini yaptıktan sonra görüntülerin olduğu dosya içinde .txt dosyalarının oluştuğun görmüş olmalısınız.
Eğer etiketleme işlemini PascalVOC formatında yaptıysanız aşağıdaki script ile sınıf sayılarını saymanız mümkün. Bu scriptin YOLO formatında çalışması için şuan için güncelleme yapmadım ama aklımda belki zamanla yapmış olurum kontrol edersiniz. Bunu yapmamın asıl amacı aslında verilerde sınıf dağılımı görmek istememdi. Sizin buna yönelik bir çalışmanız olursa görmekten memnuniyet duyarım.
classCount.py dosyasına gider.
Etiketleme işlemleri bittikten sonra sıra verilerimizi eğitim (train), doğrulama(validation) ve test datası olarak ayırmaya geldi. Verilerimizi ayırmamızın nedeni model eğitim yaparken belli aralıklarla daha önce görmediği görüntü üzerinden kendini test edecek ve testin sonucuna göre ağırlıklarını güncelleyecektir.
Val ve Test datasının bütün datamıza oranı %10 veya %20 oranında olması yeterli olacaktır. Bu oranlara literatürde farklı kaynaklarda denk gelmiş olmalısınız. Dilerseniz farklı oranda test datası ayırabilirsiniz fakat unutmamanız gereken temel işlem eğitim datasıdır yeterince eğitim verisi vermediğiniz model fazlaca doğrulama ve test datası kullansa da işe yaramayacaktır.
Bu datasetsplit python scriptini kullanarak verilerinizin istediğiniz kadarını eğitim, doğrulama ve test datası olarak ayırabilirsiniz.(bu örnekte %80,%10,%10)
Burada unutulmaması gereken xlm - YOLO dönüşüm yada etiketleme işlemlerini bitirmiş olmalısınız. Bu işlem bir .txt dosyası içinde görüntülerin adresini belirten liste oluşturacak. YOLO bu adreste hem görüntüyü hem de aynı isimde txt dosyası arayarak eğitime başlayacak.
yürütülecek kod:
pyhon dataset_split.py ./dataset_file train.txt val.txt test.txt 0.1 0.1
Bu kodla beraber train,val,test adında 3 adet .txt oluşacak artık eğitim yapmaya bir adım daha yaklaşmış olacağız. Kodun sonundaki ondalık değerler verinin yüzdelik kısımlarını val ve test olarak alacak.
Artık Yolov5 ortamına geçebiliriz. İlk girişte bahsettiğim Yolov5 kurulumunu Şuradan yaptıysanız artık bahsedeceğim dosyaların sizin bilgisayarınızda da bulunduğunu kabul ediyorum.
Elimizde verilerimiz( hepsi bir klasörde bulunabilir örneğin images) ve train.txt, val.txt, test.txt dosları bulunmakta. Bunları öncelikle yolov5 dosyası içinde data klasörü altına alıyoruz yada siz baştan beri orada çalışmış olabilirsiniz. Daha sonra yararlanmak istediğimiz modele karar veriyoruz.
Bilgisayarımızın özellikleri bu modeli seçmemizde etkili, benim bilgisayarım 16 MB RAM 4 GB Ekran kartına sahip buda en düşük modeli yani Yolov5s modelini seçmeme neden oluyor. Daha farklı model seçtiğimde maalesef bellek taşması yaşanma durumu oluyor.
Dikkat klasör durumları YOLOv5 sürümlerine göre faklılık gösterebilir.
Bu bilgilerden hareketle öncelikle data altında coco.yaml dosyasını yeni oluşturduğumuz data/modellerim klasörü oluşturarak onun altına alıyoruz ve adını istediğimiz gibi veriyoruz benim durumumda adı trafficsign.yaml oluyor ve onu düzenliyoruz.
train: ../train.txt
val: ../val.txt
test: ../test.txt
# number of classes
nc: 4
# class names
names: ['Dur_Tabelasi', 'Durak', 'Isik', 'Park' ]
Düzenlemesini yapıyor ve kaydediyoruz. Burada sınıf sayımızın 4 adet olduğunu ve isimlerini veriyoruz ayrıca train, val ve test dosyalarını bulunduğu klasörden bir üste çıkıp bulmasını söylüyoruz bu sizde farklılık gösterebilir kendinize uydurabilirsiniz.
Bir sonraki konuya geçmeden önce ufak bir hatırlatma yapmak istiyorum eğer YOLOv5 hiperparametrelerine müdahalede bulunmak istiyorsanız -ki başlangıç aşamasındaysanız tavsiye etmiyorum- hyp.*.yaml dosyalarından yararlanabilirsiniz.
YOLOv5 modellerinden çalışmak isteğiniz modeli Buradan indirebilir ve YOLOv5 klasör yapısı altında ağırlıklar(weights) klasörüne taşıyabilirsiniz.
Evet büyük oranda hazırlığımızı bitirdik şimdi sıra eğitim aşamasına geldi.
YOLOv5 ana klasöründe train.py dosyası ile eğitime başlayacağız.
Yürütülecek kod: ( önceki yazıda bahsettiğimiz anaconda ortamınızı aktive etmeyi unutmayın)
conda activate yolov5
python train.py --img-size 640 --batch 2 --epochs 100 --data ./data/modellerim/trafficsign.yaml --cfg ./models/yolov5s.yaml --weights ./weights/yolov5s.pt --project "trafficsign"
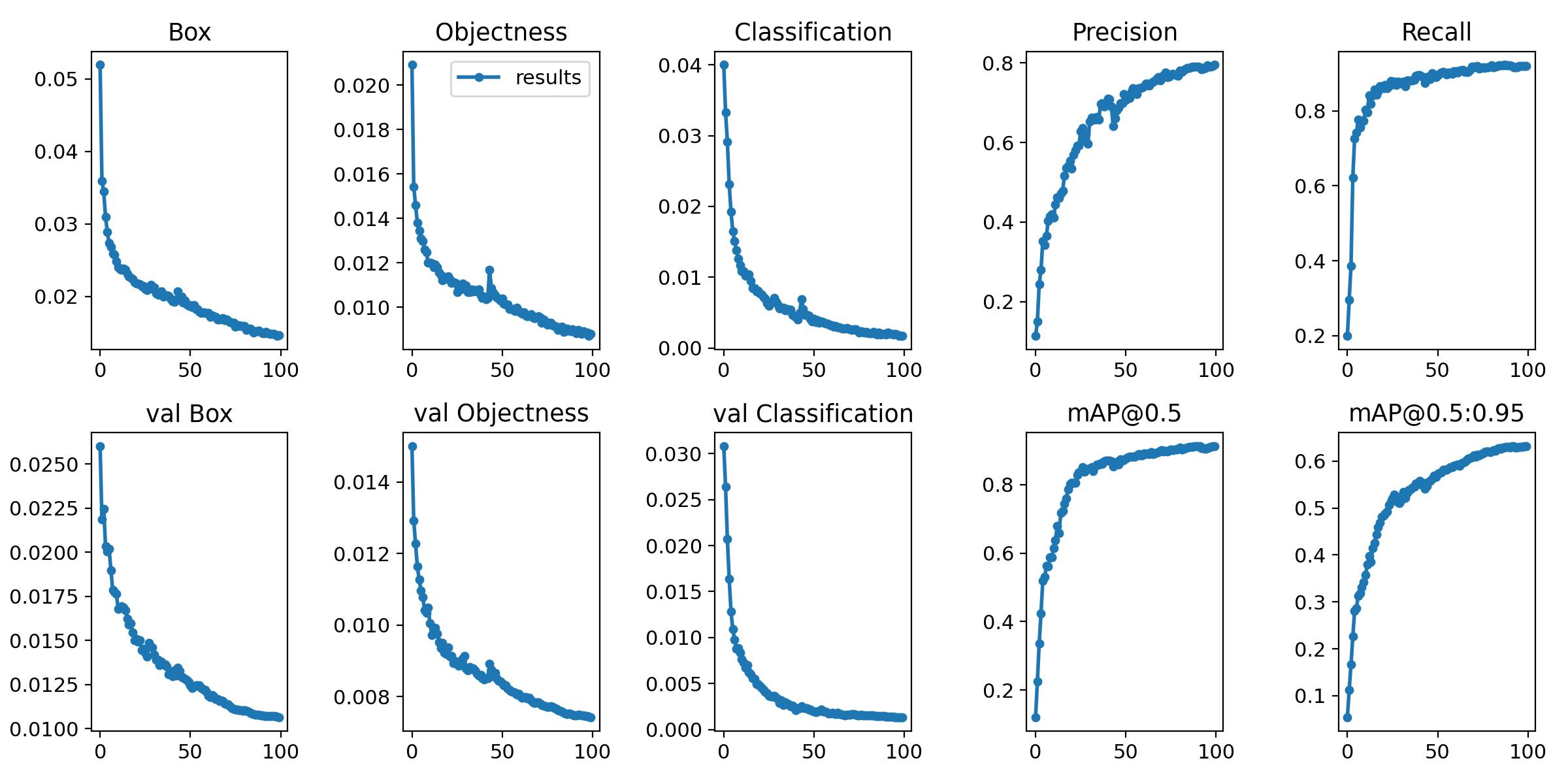
Yukarıdaki kod ile görüntüleri 640 ölçeğinde işlemesini tek seferde 2 grup (batch) ile çalışmasını, yüz nesillik bir eğitim(epochs) yapmasını kendi ayar dosyamızın yolunu ve ayrıca kullanacağımız önceden eğitilmiş ağırlık dosyasını ve en sonunda da proje adımızı veriyoruz.
Burada işlem gücünüze göre batch ayarını 2'nin katı olacak şekilde arttırabilirsiniz. -epochs sayınızda daha sonra log'taki loss ve train çizgisine bakarak azaltıp arttırabilirsiniz. Burada train çizginizin düzleşmesi artık öğrenme olmadığını göstereceğinden eğitimi kesebilirsiniz belli aralıklarla eğitimi oto. kaydedecektir.
Bu noktada transfer öğrenme yapacaksanız şuradan detaylı şekilde bilgi alabilirsiniz. Burada temelde etkilenmesini istemediğiniz katmanların dondurulması gerekmekte. Eğer omurganın dondurulmasını istiyorsanız kod bloğuna --freeze 10 yada tüm katmanların dondrulmasını istiyorsanız --freeze 24 demeniz gerekmekte. Yani kod bloğu aşağıdaki gibi olacaktır. Omurganın dondurulması az veri ile başarılı sonuçlar verecektir.
conda activate yolov5
python train.py --img-size 640 --batch 2 --epochs 100 --data ./data/modellerim/trafficsign.yaml --cfg ./models/yolov5s.yaml --weights ./weights/yolov5s.pt --project "trafficsign" --freeze 10
Daha önceden eğitilmiş bir modelin sonradan başka durumlara uyarlanmasında başarısının en önemli etkeni anchor box'tır. Daha önceden eğitilen modelden benzer yapıda nesne tespiti yapıyorsanız muhtemelen sorun yaşamazsınız fakat farklı bir senaryoda modelin derinliklerine inip hiperparametrelerini değiştirmek gerekecektir.
Şimdi eğitimimizi devam ederken öğrenme durumunu ön izlemek için farklı yollarımız var. Çevrimiçi araç olan wandb veya tensorflow'ın aracı olan tensorboard kullanabiliriz yada eğitim sırasında yolov5 proje dosyanıza sonuçları gösteren görüntü ve dosyaları oluşturacaktır. Ben bu durumda tensorboard'ı kullanacağım kendisi yolov5 kurulumda zaten kurulmuştu. Tek yapmanız gereken YOLOv5 ana klasöründe oluşan projemiz trafficsign klasörünü gösterip kodu çalıştırmak olacaktır. Kendisi localhost altında eğitim durumu hakkında detaylı bir grafik oluşturacaktır.
tensorboard --logdir trafficsign
Yazı gittikçe uzamaya başladı önemli konulara en azından soru işareti oluşturması açısından değinmeden geçmekte istemiyorum ama yazı okuma eşiğini geçti kusura bakmayın buraya kadar dayanabildiyseniz sabrınıza en içten saygılarımı sunuyorum.
Eğitim başladı loglardan ne durumda olduğunu gördük son olarak ortaya çıkan ağırlık dosyamız ile sonuçları görmeye geldi sıra.
Kod örneği:
python detect.py --weights trafficsign/weights/best.pt --img 640 --source 0
Burada kendi eğitilen ağırlığımız olan trafficsign/weights/best.pt yolunuz ve --source 0 girerek webcam açılmasını sağlamış oluyoruz siz klasör, görüntü yada video verebilirsiniz. Sonuçlar runs klasörü altında detect'in altında olacaktır.

Bana katlandığınız için teşekkür ederim, hata yaptıysam lütfen uyarmayı unutmayın yazının daha fazla uzamaması için susuyor ve hepinize iyi öğrenmeler diliyorum.